This is a second post about “argocding” your infrastructure. First can be found here .
There I’ve tried using Applications for deploying. Here I will try to show an example with ApplicationSets. As in the previous article, I will be installing VPA
and Goldilocks
So let’s prepare a base. We have 3 clusters:
- cluster-1
- cluster-2
- cluster-3
With
ApplicationSetsyou have an incredible amount of ways to deploy stuff. So what I’m doing may look super-different from what you would do
I’m creating 3 manifests, one for each cluster.
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: helm-releases
namespace: argo-system
spec:
syncPolicy:
preserveResourcesOnDeletion: true
generators:
- git:
repoURL: https://git.badhouseplants.net/allanger/helmfile-vs-argo.git
revision: argo-applicationset-main
files:
- path: "cluster2/*"
- git:
repoURL: https://git.badhouseplants.net/allanger/helmfile-vs-argo.git
revision: argo-applicationset-main
files:
- path: "common/*"
template:
metadata:
name: "{{ argo.application }}"
namespace: argo-system
spec:
project: "{{ argo.project }}"
source:
helm:
valueFiles:
- values.yaml
values: |-
{{ values }}
repoURL: "{{ chart.repo }}"
targetRevision: "{{ chart.version }}"
chart: "{{ chart.name }}"
destination:
server: "{{ argo.cluster }}"
namespace: "{{ argo.namespace }}"
Manifests with a setup like this have only one values that is really different, so we could create just one manifest that would look like that:
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: helm-releases
namespace: argo-system
spec:
syncPolicy:
preserveResourcesOnDeletion: true
generators:
- git:
repoURL: https://git.badhouseplants.net/allanger/helmfile-vs-argo.git
revision: argo-applicationset-main
files:
- path: "$CLUSTER/*"
- git:
repoURL: https://git.badhouseplants.net/allanger/helmfile-vs-argo.git
revision: argo-applicationset-main
files:
- path: "common/*"
template:
metadata:
name: "{{ argo.application }}"
namespace: argo-system
spec:
project: "{{ argo.project }}"
source:
helm:
valueFiles:
- values.yaml
values: |-
{{ values }}
repoURL: "{{ chart.repo }}"
targetRevision: "{{ chart.version }}"
chart: "{{ chart.name }}"
destination:
server: "{{ argo.cluster }}"
namespace: "{{ argo.namespace }}"
And add a step in the CI pipeline, where we’re substituting a correct value instead of the variable. But since I’m not really implementing a CI, I will create 3 manifests.
Then I need to add generators in the feature branch:
#/common/vpa.yaml
---
argo:
cluster: https://kubernetes.default.svc
application: vpa
project: default
namespace: vpa-system
chart:
version: 1.6.0
name: vpa
repo: https://charts.fairwinds.com/stable
values: |
updater:
enabled: false
#/cluster2/goldilocks.yaml
---
argo:
cluster: https://kubernetes.default.svc
application: goldilocks
project: default
namespace: vpa-system
chart:
version: 6.5.0
name: goldilocks
repo: https://charts.fairwinds.com/stable
values: |
And the main problem here is that values are passed as a string. So you can’t separate them into different files, use secrets or share common values. That can be solved with multi-source apps that came with ArgoCD 2.6, but I can’t say that they are production-ready yet. Also, I’ve read that ApplicationSets can be used to separate values and charts, but it seemed a way too complicated to me back then, and I think that with ArgoCD 2.7 this problem will be completely solved, so I’m not sure that it makes sense to check that approach now.
Next thing is that Git generators are pointed to a specific branch, so I have two problems. How to test changes on the cluster-test and how to view diffs.
Test changes
This problem is solvable, I will show on a cluster-2 example, because I don’t have 3 clusters running locally, but this logic should apply to the test cluster.
After you add new generators files, you need to deploy them to the test cluster, and you also need not override what’s being tested by other team-members. So the best option that I currently see, is to get an ApplicationSet manifest that is already deployed to k8s and add new generators to it. So it looks like this:
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: helm-releases
namespace: argo-system
spec:
syncPolicy:
preserveResourcesOnDeletion: true
generators:
- git:
repoURL: https://git.badhouseplants.net/allanger/helmfile-vs-argo.git
revision: argo-applicationset-main
files:
- path: "cluster2/*"
- git:
repoURL: https://git.badhouseplants.net/allanger/helmfile-vs-argo.git
revision: argo-applicationset-main
files:
- path: "common/*"
# This should be added within CI and removed once a the branch is merged
- git:
repoURL: https://git.badhouseplants.net/allanger/helmfile-vs-argo.git
revision: argo-applicationset-updated
files:
- path: "common/*"
- git:
repoURL: https://git.badhouseplants.net/allanger/helmfile-vs-argo.git
revision: argo-applicationset-updated
files:
- path: "cluster2/*"
template:
metadata:
name: "{{ argo.application }}"
namespace: argo-system
spec:
project: "{{ argo.project }}"
source:
helm:
valueFiles:
- values.yaml
values: |-
{{ values }}
repoURL: "{{ chart.repo }}"
targetRevision: "{{ chart.version }}"
chart: "{{ chart.name }}"
destination:
server: "{{ argo.cluster }}"
namespace: "{{ argo.namespace }}"
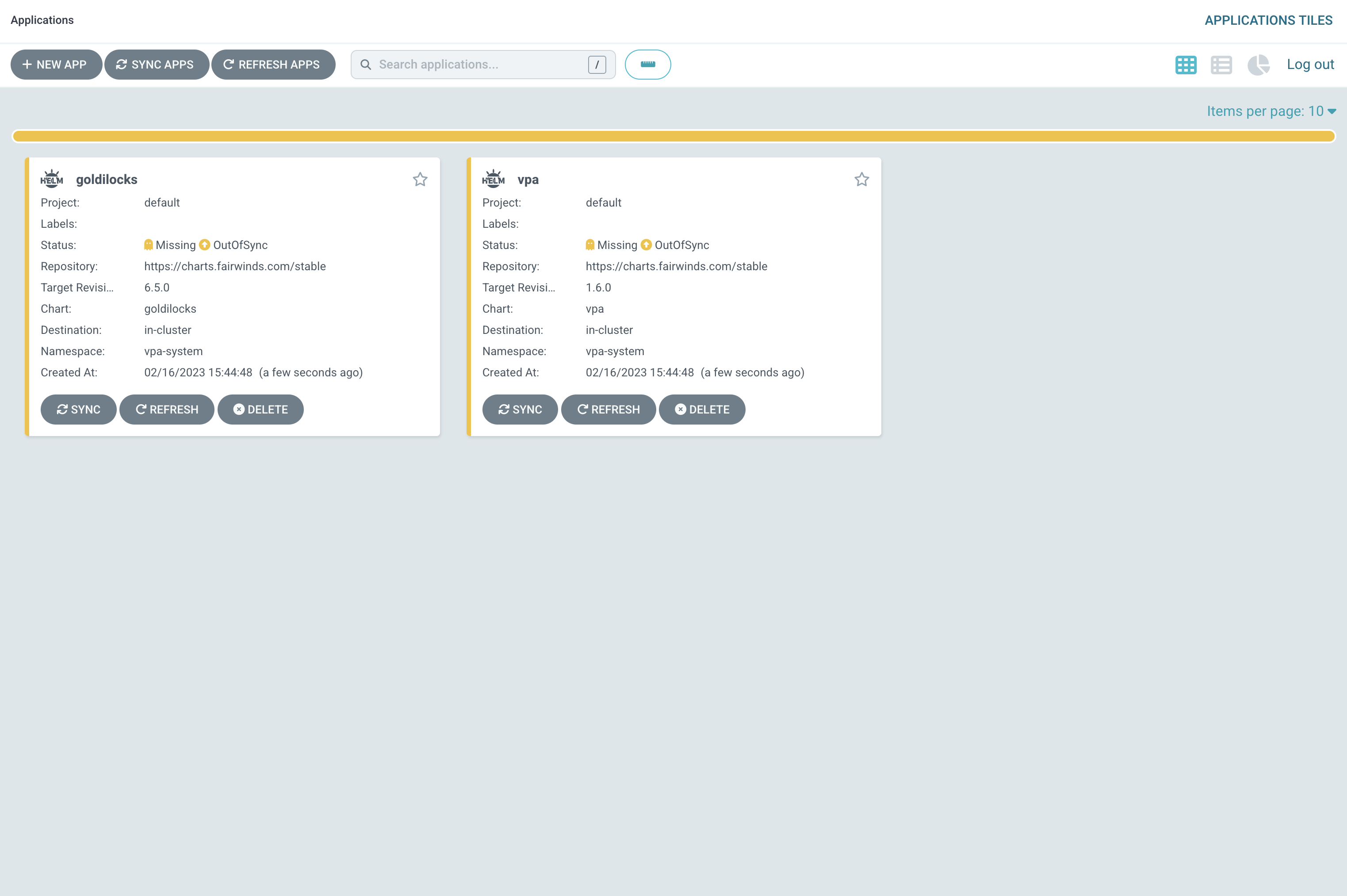
After applying this change, this what I’ve got
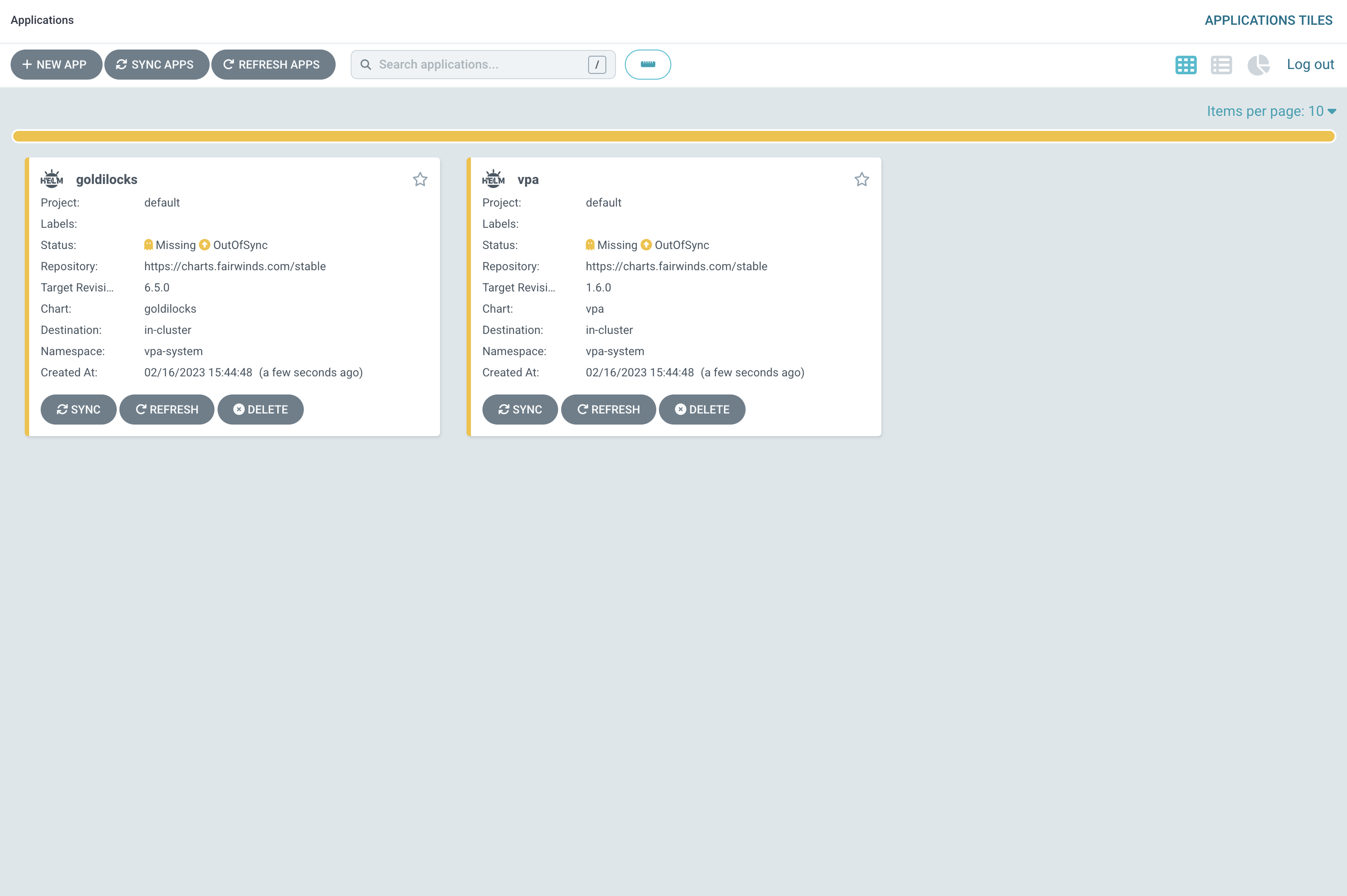
Those applications should be deployed automatically within a pipeline. So steps in your pipeline would look like that:
- Get current
ApplicationSetmanifest from Kubernetes - Add new generators
- Sync applications with argocd cli
But I’m not sure what going to happen if you have two different pipelines at the same time. Probably, changes will be overwritten but the pipeline that is a little bit slower. But I think that it can be solved without a lot of additional problems. And also I don’t think that it’s a situation that you will have to face very often, so you can just rerun your pipeline after all.
Diffs
Diffs are not supported for ApplicationSets at the moment, and I’m not sure when they will be: https://github.com/argoproj/argo-cd/issues/10895
And with the diffing situation from the previous article, I think that they will not work the way I’d like them to work.
But I think that the easiest way to deal with them right now, would be adding git generators not only to a test cluster, but to all clusters, add to those applications an additional label (e.g. test: true), and sync only those applications that don’t have this label. So the whole pipeline for branch would look like:
Feature branch
- Get current
ApplicationSetmanifests from Kubernetes (each cluster) - Add new generators (each cluster)
- Sync applications with argocd cli (only test cluster) Main branch (merged)
- Get current
ApplicationSetmanifests from Kubernetes (each cluster) - Remove obsolete generators (each cluster)
- Sync applications with argocd cli (each cluster and filter by label not to sync those, that are not merged yet)
But I’m not sure exactly how to manage these
testlabels. They can be added manually to generators files, but then you can’t be sure that one won’t forget to do it, so I think that, if possible, they should be added to generators inside anApplicationSetmanifest, or added to applications right after they were created by anApplicationSet, but the second way is not the best, because if themainpipeline is faster than feature’s one, you will have it installed in a production cluster.
Conclusion
I like this way a way more than simple Applications, especially with multi-source applications. I think that the main problem with this approach are complicated CI/CD pipelines. And I don’t like that for diffing you need to have something added to prod clusters. Diff must be safe, and if you add 1000 generator files and push them, you will have 1000 new applications in you ArgoCD. I’m not sure how it’s going to handle it. And since ArgoCD is something that is managing your whole infrastructure, I bet, you want it to work like a charm, you don’t want to doubt how it’s going to survive situations like this.
Amount of changes is not big, pretty close to helmfile, I’d say. And the more common stuff you have, the less you need to copy-paste. You can see the PR here: https://git.badhouseplants.net/allanger/helmfile-vs-argo/pulls/3
Thanks,
Oi!